
TL;DR
Mixture of Experts (MoE)는 딥러닝 모델의 연산 효율성을 높이기 위해 개발된 아키텍처 패턴입니다. 이는 단일 모델이 아닌 여러 개의 '전문가(Expert)' 서브 네트워크를 구성하고, '게이팅 네트워크(Gating Network)' 또는 '라우터(Router)'를 이용해 입력 토큰별로 가장 적합한 소수(Top-K)의 전문가만 활성화하는 희소성(Sparsity) 기반 조건부 연산을 특징으로 합니다. 이 방식을 통해 전체 파라미터 수는 대규모로 확장하면서도, 실제로 추론 및 학습 시 활성화되는 파라미터는 적어 계산 비용(FLOPs)을 절감하고 속도를 향상시킵니다. 최근 Mistral의 Mixtral 8x7B 같은 대규모 언어 모델(LLM)에 성공적으로 적용되어 효율적인 모델 확장의 핵심 기술로 주목받고 있습니다.
1. MoE(Mixture of Experts) 아키텍처의 기본 원리
Mixture of Experts (MoE)는 기계 학습, 특히 딥러닝 분야에서 모델의 용량(Capacity)과 효율성(Efficiency)을 동시에 확보하기 위해 고안된 구조입니다. 기존의 밀집(Dense) 신경망 모델이 모든 입력 데이터에 대해 모든 파라미터를 활성화하는 것과 달리, MoE는 입력 데이터의 특성에 따라 필요한 일부 파라미터만 활성화하는 조건부 연산(Conditional Computation) 방식을 도입합니다.
1.1. MoE의 핵심 구성 요소
MoE 아키텍처는 주로 두 가지 핵심 구성 요소로 이루어지며, 이는 트랜스포머(Transformer) 모델의 MLP(Multi-Layer Perceptron) 레이어를 대체하는 형태로 구현됩니다 (출처: MachineLearningMastery.com, 2025-09-12).
| 구성 요소 | 역할 및 기능 | 상세 설명 |
| 전문가 네트워크 (Experts) |
데이터의 특정 영역을 처리하도록 훈련된 개별 서브 네트워크 (일반적으로 FFN) | 개의 독립적인 신경망()으로 구성되어 있으며, 각 전문가는 입력의 특정 측면을 전문적으로 처리합니다. |
| 게이팅 네트워크/라우터 (Router/Gating Network) |
입력 토큰을 받아 어떤 전문가를 활성화할지 결정하고 가중치를 할당하는 네트워크 | 입력 에 대해 각 전문가의 가중치 또는 확률 분포를 출력하며, 일반적으로 기법을 사용하여 가장 높은 점수를 받은 개의 전문가만 선택합니다. |
MoE의 최종 출력 는 게이팅 네트워크의 가중치 Gi(x)와 선택된 전문가의 출력 Ei(x)를 조합하여 계산됩니다.
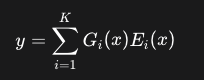
Why it matters: MoE는 모든 파라미터를 사용하지 않아도 되기 때문에, 모델의 총 파라미터 수를 극적으로 늘려 모델의 용량을 키울 수 있습니다. 이는 더 많은 '지식'을 모델에 저장할 수 있게 하면서도, 실제 계산량은 작은 '활성 파라미터' 수에 비례하여 유지할 수 있게 합니다.
2. 희소성(Sparsity)을 통한 효율성 확보
MoE의 가장 큰 장점은 희소성(Sparsity)에 기반한 효율성입니다. 전통적인 밀집(Dense) 모델이 1000억 개의 파라미터를 가지고 있다면, 모든 입력 토큰 처리 시 1000억 개의 파라미터 전체를 사용합니다. 반면, MoE 모델은 전체 파라미터는 1000억 개일지라도 라우터가 로 설정되어 있다면, 입력 토큰당 활성화되는 파라미터(Active Parameters)는 훨씬 적은 수치(예: 1000억 개 중 100억 개)에 불과합니다 (출처: Mixture of Experts (MoE) vs Dense LLMs, 2025-05-01).
2.1. 계산 비용 절감 및 속도 향상
- 계산량(FLOPs) 감소: 희소성 덕분에 MoE 모델은 동일한 총 파라미터 규모의 밀집 모델 대비 추론 시 필요한 부동소수점 연산(FLOPs)의 양을 획기적으로 줄일 수 있습니다 (출처: Advances in Foundation Models, 2025-08-02). 특정 연구에서는 최대 5배까지 연산량을 감소시킬 수 있다고 보고되었습니다.
- 학습 및 추론 속도: 활성화 파라미터의 감소는 학습 시간과 추론 지연 시간(Latency) 감소로 이어집니다. 예를 들어, Google의 Switch Transformer는 기존 GPT-3 대비 학습 시간을 17% 단축하는 효과를 보였습니다 (출처: velog, 2024-11-29).
2.2. 모델 용량(Capacity) 확장
MoE는 모델의 지식 용량을 계산 비용의 선형 증가 없이 확장하는 실용적인 해결책입니다 (출처: IBM). 전체 파라미터 수가 수천억 개에 달하는 모델을 구성할 수 있으며, 이는 모델이 다양한 도메인과 복잡한 패턴을 학습하고 기억할 수 있는 잠재력을 크게 높여줍니다.
| 비교 항목 | 밀집 모델 (Dense Model) | 희소 MoE 모델 (Sparse MoE Model) |
| 총 파라미터 수 | 모델 용량과 계산 비용이 정비례 | 모델 용량을 매우 크게 확장 가능 |
| 활성화 파라미터 수 | 항상 전체 파라미터 활성화 | 입력 토큰당 소수()의 파라미터만 활성화 |
| 계산 비용(FLOPs) | 높음 (총 파라미터 수에 비례) | 낮음 (활성화 파라미터 수에 비례) |
| 효율성 | 제한적 | 높음 (대규모 확장 시 유리) |
3. MoE의 구현 및 최신 연구 동향
MoE 아키텍처를 실제로 구현하고 운영하는 과정에는 몇 가지 기술적인 과제와 이를 해결하기 위한 최신 연구가 진행되고 있습니다.
3.1. 라우팅 메커니즘과 부하 분산
MoE 모델의 성능은 게이팅 네트워크의 라우팅(Routing) 전략에 크게 좌우됩니다 (출처: Optimizing MoE Routers, 2025-06-19).
- Top-K 라우팅: 가장 일반적인 방법으로, 게이팅 네트워크가 계산한 점수 중 가장 높은 개의 전문가를 선택합니다. Mixtral 8x7B는 라우팅을 사용하며, 8개의 전문가 중 2개만 활성화합니다 (출처: Analytics Vidhya, 2024-12-20).
- 부하 분산 (Load Balancing): 특정 전문가에게만 입력 토큰이 집중되는 부하 불균형 문제를 해결하는 것이 중요합니다. 만약 특정 전문가가 '과부하'되거나, 반대로 사용되지 않는 '죽은 전문가(Dead Expert)'가 발생하면 모델의 성능이 저하될 수 있습니다. 이를 막기 위해 학습 과정에서 보조 손실(Auxiliary Loss)을 추가하여 모든 전문가가 고르게 사용되도록 유도합니다 (출처: Advances in Foundation Models, 2025-08-02).
3.2. MoE의 트랜스포머 적용
대부분의 최신 MoE 기반 LLM은 디코더 전용 트랜스포머 아키텍처를 기반으로 합니다 (출처: yongggg's Blog, 2025-04-16). 트랜스포머 블록 내의 기존 밀집 FFN(Feed-Forward Network) 레이어를 MoE 레이어로 대체하는 방식이 주로 사용됩니다 (출처: MachineLearningMastery.com, 2025-09-12).
MoE를 도입한 주요 LLM의 사례는 다음과 같습니다.
- Mixtral 8x7B (Mistral AI): 8개의 전문가 중 2개의 전문가를 활성화하는 희소 MoE 모델의 대표적인 오픈소스 사례입니다.
- GPT-4 (OpenAI): 독점 LLM인 GPT-4 역시 MoE 아키텍처를 활용한다는 것이 업계에서 널리 알려져 있습니다 (출처: NVIDIA Technical Blog, 2024-03-14).
- Switch Transformer (Google): MoE를 대규모로 적용한 초기 성공 사례로, 전문가 수를 1개만 활성화하는 라우팅 방식을 사용했습니다 (출처: velog, 2024-11-29).
Why it matters: 라우팅과 부하 분산은 MoE 모델의 실질적인 효율성과 안정성을 결정하는 중요한 요소입니다. 특히 분산 환경에서의 배포와 운영에서 전문가 간의 통신 오버헤드를 관리하고 균형 잡힌 부하를 유지하는 것이 실무자의 주요 과제가 됩니다.
4. 밀집 모델(Dense Model)과의 비교
MoE 아키텍처는 밀집 모델 대비 명확한 이점을 제공하지만, 동시에 고유한 도전 과제도 가지고 있습니다.
4.1. 성능 및 데이터 효율성
MoE 모델은 동일한 계산 예산(Compute Budget) 내에서 훈련할 때 밀집 모델 대비 우수한 일반화 성능을 보이며, 동일한 성능을 달성하는 데 더 적은 양의 훈련 데이터를 필요로 합니다. (출처: Scaling Laws Across Model Architectures, 2024-10-08). 한 연구에서는 MoE 모델이 밀집 모델 대비 약 16.37% 더 나은 데이터 활용도를 보인다고 분석했습니다. 이는 LLM 훈련 시 데이터 제약을 완화하는 중요한 이점입니다.
4.2. 주요 도전 과제
- 메모리 요구 사항: 추론 시 활성화되는 파라미터는 적지만, 모델 전체의 총 파라미터 수가 매우 크기 때문에, 모델을 메모리(VRAM)에 로드하는 데 필요한 자원은 밀집 모델보다 훨씬 높을 수 있습니다 (출처: Mixture of Experts (MoE) vs Dense LLMs, 2025-05-01).
- 복잡한 분산 처리: MoE는 각 토큰을 다른 전문가에게 분산시키고 그 결과를 다시 취합해야 하므로, 분산 학습 및 추론 환경에서 전문가 간의 통신(All-to-All Communication) 오버헤드가 발생할 수 있습니다. 이는 구현을 복잡하게 만들고, 최적화되지 않은 경우 성능 저하를 초래할 수 있습니다 (출처: Weights & Biases - Wandb).
Why it matters: MoE는 규모 대비 효율적이지만, 대규모 파라미터로 인한 높은 VRAM 요구 사항은 여전히 로컬 환경이나 소규모 클러스터에서의 실무적 배포를 어렵게 하는 제약 사항으로 작용합니다. 따라서 MoE 모델의 효율성은 주로 대규모 분산 환경에서 극대화됩니다.
결론 (요약 정리)
Mixture of Experts(MoE) 아키텍처는 딥러닝, 특히 LLM 분야에서 모델의 용량을 계산 비용의 비선형적 증가 없이 확장할 수 있는 핵심 기술입니다. 이는 라우터를 통해 입력 토큰별로 소수의 전문가(Experts)만 활성화하는 희소성(Sparsity) 기반 조건부 연산을 통해 달성됩니다. 이로 인해 MoE 모델은 밀집 모델 대비 추론 시 FLOPs가 크게 감소하고, 동일 계산 예산 하에서 더 우수한 성능 및 데이터 효율성을 보입니다. 주요 모델로는 Mixtral 8x7B, Switch Transformer 등이 있으며, 현재 연구는 부하 분산 및 최적의 라우팅 메커니즘 개발에 집중되어 있습니다. 실무 도입 시 총 파라미터로 인한 높은 VRAM 요구 사항과 복잡한 분산 통신 관리가 주된 고려 사항입니다.
References
- Applying Mixture of Experts in LLM Architectures | NVIDIA Technical Blog | 2024-03-14 | https://developer.nvidia.com/blog/applying-mixture-of-experts-in-llm-architectures/
- What is Mixture of Experts? | Analytics Vidhya | 2024-12-20 | https://www.analyticsvidhya.com/blog/2024/12/mixture-of-experts-models/
- Mixture of Experts (MoE) vs Dense LLMs | maximilian-schwarzmueller.com | 2025-05-01 | https://maximilian-schwarzmueller.com/articles/understanding-mixture-of-experts-moe-llms/
- Scaling Laws Across Model Architectures: A Comparative Analysis of Dense and MoE Models in Large Language Models | arXiv | 2024-10-08 | https://arxiv.org/html/2410.05661v1
- Advances in Foundation Models: Sparse Mixture‑of‑Experts for Efficient Inference | Medium | 2025-08-02 | https://medium.com/@fahey_james/advances-in-foundation-models-sparse-mixture-of-experts-for-efficient-inference-be5b106b4de5
- Optimizing MoE Routers: Design, Implementation, and Evaluation in Transformer Models | arXiv | 2025-06-19 | https://arxiv.org/html/2506.16419v1
- [TREND] 트렌스포머 이후의 차세대 아키텍쳐: MoE, SSM, RetNet, V-JEPA | velog | 2024-11-29 | https://velog.io/@euisuk-chung/%ED%8A%B8%EB%A0%8C%EB%93%9C-%ED%8A%B8%EB%A0%8C%EC%8A%A4%ED%8F%AC%EB%A8%B8-%EC%9D%B4%ED%9B%84%EC%9D%98-%EC%B0%A8%EC%84%B8%EB%8C%80-%EC%95%84%ED%82%A4%ED%85%8D%EC%B3%90-MoE-SSM-RetNet-V-JEPA
- What is mixture of experts? | IBM | N/A | https://www.ibm.com/think/topics/mixture-of-experts