
TL;DR
Attention Mechanism은 모델이 입력 시퀀스의 모든 부분을 동일하게 처리하는 대신, 현재 작업에 가장 관련성 높은 부분에 가중치를 부여하여 집중하게 하는 딥러닝 기법입니다. 이는 인간의 선택적 집중 능력을 모방한 것으로, 2014년 Bahdanau 등이 기계 번역 모델의 고정 크기 인코딩 벡터 문제(병목 현상)를 해결하기 위해 처음 도입했습니다. 이후 2017년 논문 "Attention Is All You Need"에서 Transformer 아키텍처가 소개되며 RNN/CNN 같은 순환/합성곱 구조 없이 오직 Self-Attention만으로 구성되어 NLP 분야의 패러다임을 전환했습니다. Attention은 Query(Q), Key(K), Value(V) 세 벡터의 상호작용을 통해 가중치를 계산하며, 이 가중치를 Value에 적용하여 최종 출력(Context Vector)을 생성합니다.
1. Attention Mechanism의 기본 개념과 등장 배경
Attention Mechanism은 딥러닝 모델이 전체 입력 데이터 중 특정 시점에서 중요한 정보를 선별적으로 포착하고 활용하도록 돕는 기술입니다. 기존의 순환 신경망(RNN) 계열의 Seq2Seq 모델은 입력 시퀀스를 고정된 크기의 Context Vector 하나로 압축했기 때문에, 입력 시퀀스가 길어질수록 초기에 입력된 정보가 손실되는 장거리 의존성(Long-Term Dependency) 및 정보 병목(Information Bottleneck) 문제가 발생했습니다.
2014년 Bahdanau 등이 제시한 Attention은 디코더가 매 출력 단어를 예측할 때 인코더의 모든 은닉 상태(Hidden State)를 참조하되, 예측에 가장 관련 있는 부분에 **Attention Weight(집중 가중치)**를 다르게 부여하여 이 문제를 완화했습니다. 이 가중치를 적용한 가중합이 새로운 Context Vector가 되어 디코더에 제공됩니다.
Attention 작동 원리: Q, K, V
Attention 함수는 기본적으로 Query(Q), Key(K), Value(V) 세 벡터를 입력으로 받아, Q와 K의 유사도(호환성)를 계산하여 Attention Weight를 얻고, 이 가중치를 V에 적용한 가중합을 최종 출력으로 산출합니다.
- Query (Q): 현재 시점에서 알고 싶은 정보(예: 디코더의 현재 상태).
- Key (K): 검색 대상 데이터의 식별자 또는 인덱스(예: 인코더의 모든 은닉 상태).
- Value (V): 실제로 검색된 정보(예: 인코더의 모든 은닉 상태).

이 식은 Scaled Dot-Product Attention의 핵심이며,

를 통해 와 간의 유사도(Attention Score)를 계산하고,
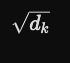
로 나누어(Scaling) 경사 소실 문제를 방지한 후, Softmax를 통해 가중치(α)를 정규화합니다.
Why it matters: Attention 메커니즘의 도입은 시퀀스 모델의 정보 병목 현상과 장거리 의존성 문제를 실질적으로 해결했으며, 이는 모델이 복잡한 문맥과 관계를 효율적으로 학습하는 기반을 마련했습니다.
2. Self-Attention과 Transformer의 등장
2017년 Google에서 발표한 논문 "Attention Is All You Need"는 순환 구조(RNN)와 합성곱 구조(CNN)를 완전히 제거하고, Self-Attention 메커니즘만을 기반으로 한 Transformer 아키텍처를 제안했습니다. 이 모델은 병렬 처리의 효율성을 극대화하여 딥러닝 모델의 학습 속도와 성능을 비약적으로 향상시켰습니다.
2.1. Self-Attention (자가 주의)
Self-Attention은 Attention Mechanism의 한 유형으로, Query, Key, Value가 모두 동일한 입력 시퀀스에서 파생된다는 특징이 있습니다. 이는 시퀀스 내의 한 단어가 그 시퀀스 내의 다른 모든 단어들과의 관계를 파악하여 자신의 표현(Representation)을 업데이트하도록 합니다.
예를 들어, "The animal didn't cross the street because it was too tired."라는 문장에서 'it'을 처리할 때, Self-Attention은 'it'이 'animal'과 더 관련이 높고 'street'과는 덜 관련이 높다는 것을 학습할 수 있습니다.
2.2. Multi-Head Attention (다중 헤드 주의)
Multi-Head Attention은 Self-Attention을 병렬로 여러 번 수행하는 방식입니다. 여기서 '헤드(Head)'는 독립적인 Q, K, V 가중치 행렬 를 가진 Attention 연산입니다.
| 구분 | 설명 |
| 다중 헤드 | 개의 다른 공간(Subspace)으로 를 투영하고 독립적으로 Attention을 계산 |
| 효과 | 모델이 다양한 관점에서 정보에 집중할 수 있게 하여, 문맥의 다양한 측면(예: 문법적 관계, 의미적 관계)을 동시에 포착 |
| 결과 | 병렬 계산된 개의 출력 벡터를 **연결(Concatenate)**하고 최종 가중치 행렬 를 곱하여 최종 출력 산출 |

Why it matters: Multi-Head Attention은 단일 Attention으로는 포착하기 어려운 복잡하고 다양한 관계를 병렬적으로 학습할 수 있게 하여, 모델의 표현력과 학습 능력을 획기적으로 향상시켰습니다.
3. Transformer의 주요 구조와 Attention 유형
Transformer는 인코더(Encoder) 스택과 디코더(Decoder) 스택으로 구성되며, 각 스택은 여러 개의 동일한 레이어를 쌓아 올린 형태입니다. 각 레이어에는 Multi-Head Attention과 Feed-Forward Network가 포함됩니다.
3.1. Encoder의 Self-Attention
인코더는 입력 시퀀스를 처리하여 문맥이 풍부한 표현(Representation)을 생성합니다. 인코더의 Self-Attention에서는 Q, K, V가 모두 인코더의 이전 레이어 출력(또는 입력 임베딩)에서 나옵니다. 이를 통해 입력 문장 내의 모든 단어 쌍 간의 관계를 계산합니다.
3.2. Decoder의 두 가지 Attention
디코더는 목표 시퀀스(Target Sequence)를 생성하며 두 가지 Multi-Head Attention 레이어를 포함합니다.
- Masked Multi-Head Self-Attention: 디코더의 첫 번째 Attention으로, 예측 시점에 미래 정보를 참조하지 못하도록 마스킹(Masking)을 적용합니다. Q, K, V는 디코더의 이전 레이어 출력에서 나옵니다.
- Encoder-Decoder Attention (Cross-Attention): 디코더의 두 번째 Attention으로, **Query(Q)**는 디코더의 이전 레이어 출력에서 가져오고, Key(K)와 Value(V)는 인코더 스택의 최종 출력에서 가져옵니다. 이를 통해 디코더는 인코더의 출력 중 현재 예측 단어에 가장 관련 있는 정보를 선택적으로 집중합니다.
Why it matters: Transformer는 순차적인 계산을 병렬 Attention 연산으로 대체하여 GPU 활용도를 극대화하고 학습 시간을 단축시켰으며, Long-Term Dependency 문제를 근본적으로 해결하여 현대 대규모 언어 모델(LLM)의 근간이 되었습니다.
결론 (요약 정리)
Attention Mechanism은 딥러닝, 특히 시퀀스 모델링 분야의 가장 중요한 혁신 중 하나입니다.
- Attention은 가중치 기반의 선택적 집중을 통해 기존 RNN의 정보 병목 문제를 해결했습니다.
- Query, Key, Value 상호작용을 기반으로 가중치를 계산하고 Context Vector를 산출합니다.
- Self-Attention은 시퀀스 내의 모든 요소 간의 관계를 모델링하며, Multi-Head Attention은 이 과정을 병렬화하여 다양한 문맥 정보를 동시에 포착합니다.
- Transformer는 오직 Attention 메커니즘으로만 구성되어 병렬 학습의 효율을 극대화하고, 현대 NLP, CV 분야를 아우르는 혁신적인 기반 아키텍처가 되었습니다.
References
- What is an attention mechanism? | IBM | N/A | https://www.ibm.com/think/topics/attention-mechanism
- What are Attention Mechanisms in Deep Learning? | freeCodeCamp | 2024-06-17 | https://www.freecodecamp.org/news/what-are-attention-mechanisms-in-deep-learning/
- Attention Mechanisms and Their Applications to Complex Systems | PMC - PubMed Central | N/A (게재일이 명확하지 않음) | https://pmc.ncbi.nlm.nih.gov/articles/PMC7996841/
- [Transformer 쉽게 이해하기] - self-attention, multi-haed attention, cross-attention, causal attention 설명과 코드 설명 | 콩스버그 - 티스토리 | 2024-01-19 | https://kongsberg.tistory.com/47
- Attention Is All You Need | arXiv | 2017-06-12 | https://arxiv.org/html/1706.03762v7
- How Attention Mechanism Works in Transformer Architecture - YouTube | YouTube | 2025-03-08 | https://www.youtube.com/watch?v=KMHkbXzHn7s
- The Attention Mechanism from Scratch | MachineLearningMastery.com | 2023-01-06 | https://machinelearningmastery.com/the-attention-mechanism-from-scratch/
'AI' 카테고리의 다른 글
| NVIDIA Isaac GR00T: 휴머노이드 로봇을 위한 범용 파운데이션 모델과 생태계 혁신 (2) | 2025.10.18 |
|---|---|
| Few-Shot Learning이란? 적은 데이터로 AI 모델을 훈련하는 원리와 활용법 (0) | 2025.10.16 |
| 알리바바의 Qwen3-VL-30B-A3B: 효율성과 성능을 모두 갖춘 오픈소스 멀티모달 AI 혁신 분석 (1) | 2025.10.11 |
| 파이썬과 Prophet으로 삼성전자 주가 예측: 시계열 분석 입문 (0) | 2025.10.10 |
| ML 성능과 효율을 동시에, LoRA(Low-Rank Adaptation) 완벽 분석 (1) | 2025.10.07 |