
WITH TEMP AS (
SELECT '과일' AS CLASS
, '사과' AS NAME
UNION ALL
SELECT '과일' AS CLASS
, '배' AS NAME
UNION ALL
SELECT '과일' AS CLASS
, '포도' AS NAME
UNION ALL
SELECT '과일' AS CLASS
, '귤' AS NAME
UNION ALL
SELECT '과자' AS CLASS
, '홈런볼' AS NAME
UNION ALL
SELECT '과자' AS CLASS
, '치토스' AS NAME
UNION ALL
SELECT '과자' AS CLASS
, '양파링' AS NAME
UNION ALL
SELECT '과자' AS CLASS
, '꼬북칩' AS NAME
UNION ALL
SELECT '음료' AS CLASS
, '콜라' AS NAME
UNION ALL
SELECT '음료' AS CLASS
, '사이다' AS NAME
)
SELECT CLASS
, STRING_AGG(NAME, ', ') WITHIN GROUP(ORDER BY NAME)
, STUFF((SELECT ', ' + NAME FROM TEMP ST1 WHERE ST1.CLASS = T1.CLASS ORDER BY NAME FOR XML PATH('')), 1, 2, '#')
FROM TEMP T1
GROUP BY CLASS
※ 오늘은 설명을 위해 임시 테이블을 WITH절 추가하여 설명할 예정입니다.
2020.09.02 - [개발 창고/데이터베이스 개발] - [SQL] WITH절 사용하기
[SQL] WITH절 사용하기
SQL문을 작성하다 보면 같은 Query구문을 반복해서 작성하는 경우가 발생합니다. 이런 경우 보통 1~2번의 반복은 개발자 입장에서 작성하지만, 잦은 반복 또는 동일 구문에 대한 조건 등의 추가로
royzero.tistory.com
아래와 같은 데이터가 있다고 가정합니다.
| 분류 | 항목 |
| 과일 | 사과 |
| 과일 | 배 |
| 과일 | 포도 |
| 과일 | 귤 |
| 과자 | 홈런볼 |
| 과자 | 치토스 |
| 과자 | 양파링 |
| 과자 | 꼬북칩 |
| 음료 | 콜라 |
| 음료 | 사이다 |
해당 데이터는 아래와 같이 WITH절을 이용하여 템프 테이블로 생성가능합니다.
WITH TEMP AS (
SELECT '과일' AS CLASS
, '사과' AS NAME
UNION ALL
SELECT '과일' AS CLASS
, '배' AS NAME
UNION ALL
SELECT '과일' AS CLASS
, '포도' AS NAME
UNION ALL
SELECT '과일' AS CLASS
, '귤' AS NAME
UNION ALL
SELECT '과자' AS CLASS
, '홈런볼' AS NAME
UNION ALL
SELECT '과자' AS CLASS
, '치토스' AS NAME
UNION ALL
SELECT '과자' AS CLASS
, '양파링' AS NAME
UNION ALL
SELECT '과자' AS CLASS
, '꼬북칩' AS NAME
UNION ALL
SELECT '음료' AS CLASS
, '콜라' AS NAME
UNION ALL
SELECT '음료' AS CLASS
, '사이다' AS NAME
)
SELECT *
FROM TEMP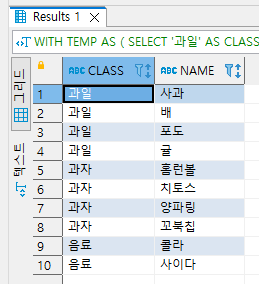
만약 각 CLASS별 NAME들을 한 컬럼에 넣고 싶다면 어떻게 해야 할까요?
| 분류 | 항목 |
| 과일 | 사과, 배, 포도, 귤 |
| 과자 | 홈런볼, 치토스, 양파링, 꼬북칩 |
| 음료 | 콜라, 사이다 |
이 경우 MSSQL에서 흔히 쓰이는 방법으로 두 가징 방법이 있습니다.
STRING_AGG 사용하기
Oracle에서 LISTAGG와 비슷한 STRING_AGG는 SQL Server 2017 이상에서만 해당 함수를 지원하기 때문에 반드시 본인이 사용하는 MSSQL을 확인하여야 하며, 운영상에서 사용하는 경우 테스트 환경과 운영환경에서의 버전을 고려해야 합니다.
| ※ 버전은 아래 Query 실행시 결과 확인이 가능합니다. SELECT @@VERSION  |
STRING_AGG의 사용 문법은 아래와 같습니다.
| STRING_AGG("대상컬럼", "구분자") [WITHIN GROUP(ORDER BY "대상컬럼명")] |

WITHIN 이후 절은 옵션사항이므로 굳이 병합되는 항목의 이름 (여기서는 NAME)이 정렬될 필요가 없는 경우에는 사용하지 않아도 됩니다.
WITH TEMP AS (
SELECT '과일' AS CLASS
, '사과' AS NAME
UNION ALL
SELECT '과일' AS CLASS
, '배' AS NAME
UNION ALL
SELECT '과일' AS CLASS
, '포도' AS NAME
UNION ALL
SELECT '과일' AS CLASS
, '귤' AS NAME
UNION ALL
SELECT '과자' AS CLASS
, '홈런볼' AS NAME
UNION ALL
SELECT '과자' AS CLASS
, '치토스' AS NAME
UNION ALL
SELECT '과자' AS CLASS
, '양파링' AS NAME
UNION ALL
SELECT '과자' AS CLASS
, '꼬북칩' AS NAME
UNION ALL
SELECT '음료' AS CLASS
, '콜라' AS NAME
UNION ALL
SELECT '음료' AS CLASS
, '사이다' AS NAME
)
SELECT CLASS
, STRING_AGG(NAME, ', ') WITHIN GROUP(ORDER BY NAME)
FROM TEMP T1
GROUP BY CLASSSTUFF ~ FOR XML 사용하기
운영환경이 MSSQL 2017 이전 버전인 경우에는 STRING_AGG를 사용할 수 없으므로 STUFF와 FOR XML을 적절히 활용하여주어야 합니다.
우선 STUFF에 대해 이야기하면,
| STUFF은 문자열의 시작위치에서 지정크기 만큼 치환문자로 치환해주는 함수입니다. STUFF("문자열", "시작위치", "지정크기", "치환문자") 예제 "가나다라마바사"라는 문자열의 시작위치인 "가"에서부터 2개의 글자를 "##"으로 "!@"로 변환한다고 가정하면 SELECT STUFF('가나다라마바사', 1, 2, '!@')  |
다음은 SELECT의 FOR XML문법에 대해 이야기해 보면
| FOR XML은 해당 결과를 XML 형태로 변환해 줍니다. MODE RAW: 각 결과를 반호나되는 단일 행(ROW)로 생성합니다. AUTO: 결과를 XML에서 중첩된 구조로 생성합니다. EXPLICIT: XML모양을 조금 더 상세하게 커스터마이징 가능합니다. PATH: EXPLICIT보다 간결하게 XML형태를 가공합니다. |
MULTI ROW를 한 개의 COLUMN에 넣으려면 우선 XML형태로 변경하여 한 개의 COLUMN으로 결과를 바꿔줄 필요가 있습니다. 때문에, FOR XML은 실제로는 MULTI ROW INTO ONE COLUMN을 위해 마련된 함수는 아니지만 조합하여 사용하기 위해서 많은 사람들이 활용하는 방법입니다.
그러기 위해서는 태그가 불필요하므로 PATH를 사용하여 태그 이외의 값으로 반환해 줍니다.
만약 아래와 같이 사용한다면
WITH TEMP AS (
SELECT '과일' AS CLASS
, '사과' AS NAME
UNION ALL
SELECT '과일' AS CLASS
, '배' AS NAME
UNION ALL
SELECT '과일' AS CLASS
, '포도' AS NAME
UNION ALL
SELECT '과일' AS CLASS
, '귤' AS NAME
UNION ALL
SELECT '과자' AS CLASS
, '홈런볼' AS NAME
UNION ALL
SELECT '과자' AS CLASS
, '치토스' AS NAME
UNION ALL
SELECT '과자' AS CLASS
, '양파링' AS NAME
UNION ALL
SELECT '과자' AS CLASS
, '꼬북칩' AS NAME
UNION ALL
SELECT '음료' AS CLASS
, '콜라' AS NAME
UNION ALL
SELECT '음료' AS CLASS
, '사이다' AS NAME
)
SELECT NAME
FROM TEMP
FOR XML PATH('')결과는 아래와 같이 NAME이란 컬럼으로 감싸진 한 개의 XML형태의 컬럼으로 반환됩니다.
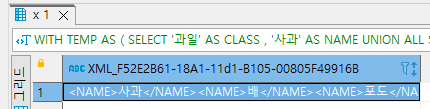
여기에서 MSSQL이 인식하지 못하도록 컬럼명을 없애주면 (ALIAS지정 또는 혼합 컬럼) 결과가 아래와 같이 보입니다.


하지만 합쳐진 COLUMN 내용에서 시작 부분에도 구분자가 붙기 때문에 이 구분자를 제거해 줄 필요가 있습니다. 이를 위해서는 두 가지 방법이 가능합니다.
1/ SUBSTRING 사용
해당 결과를 SUBSTRING을 구분자 크기(공란포함)인 3부터 무한대로 잘라주는 방법입니다.


2/ STUFF 사용

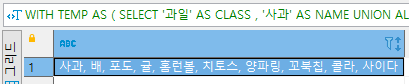
결론적으로 맨 처음 이야기한 STRING_AGG와 동일한 결과를 내기 위해서는 아래와 같이 실해주면 됩니다.
WITH TEMP AS (
SELECT '과일' AS CLASS
, '사과' AS NAME
UNION ALL
SELECT '과일' AS CLASS
, '배' AS NAME
UNION ALL
SELECT '과일' AS CLASS
, '포도' AS NAME
UNION ALL
SELECT '과일' AS CLASS
, '귤' AS NAME
UNION ALL
SELECT '과자' AS CLASS
, '홈런볼' AS NAME
UNION ALL
SELECT '과자' AS CLASS
, '치토스' AS NAME
UNION ALL
SELECT '과자' AS CLASS
, '양파링' AS NAME
UNION ALL
SELECT '과자' AS CLASS
, '꼬북칩' AS NAME
UNION ALL
SELECT '음료' AS CLASS
, '콜라' AS NAME
UNION ALL
SELECT '음료' AS CLASS
, '사이다' AS NAME
)
SELECT CLASS
, STUFF((SELECT ', ' + NAME FROM TEMP ST1 WHERE ST1.CLASS = T1.CLASS ORDER BY NAME FOR XML PATH('')), 1, 2, '#')
FROM TEMP T1
GROUP BY CLASS'개발 창고 > Database' 카테고리의 다른 글
| [MySQL] Limit 사용하기 (0) | 2023.02.22 |
|---|---|
| [MySQL] CONNECT BY 구현하기 (0) | 2023.02.13 |
| [ORACLE] ORA-12505 (0) | 2023.01.09 |
| [MSSQL] 문자열 나누기 - SPLIT (0) | 2022.12.05 |
| [SQL] 연산자 (0) | 2022.11.13 |